May 2021: I will be joining MILA as a graduate student this fall '21.
January 2021: Our WACV paper's video is now out on YouTube. Watch it here.
January 2021: I will be speaking at the W&B Deep Learning Salon on "From Smooth Activations to Robustness to Catastrophic Forgetting". I will be joined by Maithra Raghu from Google Brain. Watch it here.
December 2020: I'm starting full time as a Machine Learning Engineer at Weights & Biases.
Research Associate IOct 2023 - May 2024 Carnegie Mellon University (CMU), Human Sensing Lab (HSL)
Supervisor: Prof. Fernando De la Torre
Research Area: Transfer of personalization on continual update of diffusion models.
Machine Learning ResearcherApril. 2022 - Feb. 2023 Morgan Stanley
Supervisor: Kashif Rasul
Research Area: Continual Learning, Time Series, Model Reprogramming
Remote Visiting Research ScholarAug. 2021 - Oct. 2023 VITA, University of Texas at Austin
Supervisor: Dr. Zhangyang Wang
Research Area: Sparsity, Robustness and Knowledge Distillation.
We propose Mish, a novel self-regularized non-monotonic activation function which can be mathematically defined as: $f(x)=xtanh(softplus(x))$. As activation functions play a crucial role in the performance and training dynamics in neural networks, we validated experimentally on several well-known benchmarks against the best combinations of architectures and activation functions. We also observe that data augmentation techniques have a favorable effect on benchmarks like ImageNet-1k and MS-COCO across multiple architectures. For example, Mish outperformed Leaky ReLU on YOLOv4 with a CSP-DarkNet-53 backbone on average precision ($AP^{val}_{50}$) by $2.1\%$ in MS-COCO object detection and ReLU on ResNet-50 on ImageNet-1k in Top-1 accuracy by $\approx 1 \%$ while keeping all other network parameters and hyperparameters constant. Furthermore, we explore the mathematical formulation of Mish in relation with the Swish family of functions and propose an intuitive understanding on how the first derivative behavior may be acting as a regularizer helping the optimization of deep neural networks.
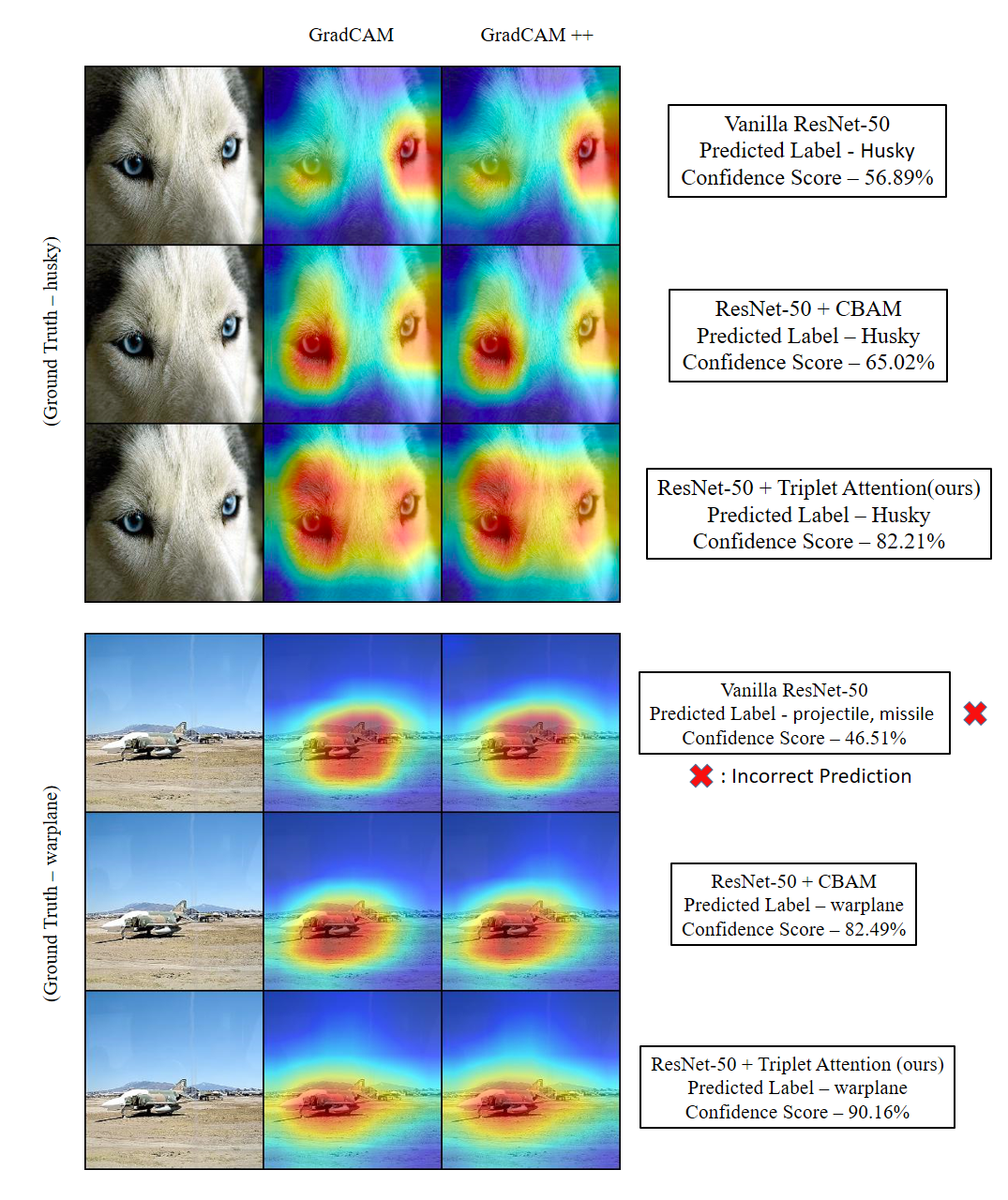
Benefiting from the capability of building interdependencies among channels or spatial locations, attention mechanisms have been extensively studied and broadly
used in a variety of computer vision tasks recently. In
this paper, we investigate light-weight but effective attention mechanisms and present triplet attention, a novel
method for computing attention weights by capturing cross-dimension interaction using a three-branch structure. For
an input tensor, triplet attention builds inter-dimensional
dependencies by the rotation operation followed by residual transformations and encodes inter-channel and spatial
information with negligible computational overhead. Our
method is simple as well as efficient and can be easily
plugged into classic backbone networks as an add-on module. We demonstrate the effectiveness of our method on
various challenging tasks including image classification on
ImageNet-1k and object detection on MSCOCO and PASCAL VOC datasets. Furthermore, we provide extensive insight into the performance of triplet attention by visually
inspecting the GradCAM and GradCAM++ results. The
empirical evaluation of our method supports our intuition
on the importance of capturing dependencies across dimensions when computing attention weights.
@inproceedings{misra2021rotate,
title={Rotate to attend: Convolutional triplet attention module},
author={Misra, Diganta and Nalamada, Trikay and Arasanipalai, Ajay Uppili and Hou, Qibin},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={3139--3148},
year={2021}
}
Language is an intricately structured system, and a key goal of NLP interpretability is to provide methodological insights for understanding how language models internally represent this structure. In this paper, we use Shapley Taylor interaction indices (STII) in order to examine how language and speech models internally relate and structure their inputs. Pairwise Shapley interactions give us an attribution measure of how much two inputs work together to influence model outputs beyond if we linearly added their independent influences, providing a view into how models encode structural interactions between inputs. We relate the interaction patterns in models to three underlying linguistic structures: syntactic structure, non-compositional semantics, and phonetic interaction. We find that autoregressive text models encode interactions that correlate with the syntactic proximity of inputs, and that both autoregressive and masked models encode nonlinear interactions in idiomatic phrases with non-compositional semantics. Our speech results show that inputs are more entangled for pairs where a neighboring consonant is likely to influence a vowel or approximant, showing that models encode the phonetic interaction needed for extracting discrete phonemic representations.
@misc{singhvi2024knowing,
title={Knowing Your Nonlinearities: Shapley Interactions Reveal the Underlying Structure of Data},
author={Divyansh Singhvi and Andrej Erkelens and Raghav Jain and Diganta Misra and Naomi Saphra},
year={2024},
eprint={2403.13106},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
The rapid evolution of software libraries poses a considerable hurdle for code generation, necessitating continuous adaptation to frequent version updates while preserving backward compatibility. While existing code evolution benchmarks provide valuable insights, they typically lack execution-based evaluation for generating code compliant with specific library versions. To address this, we introduce GitChameleon, a novel, meticulously curated dataset comprising 328 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. GitChameleon rigorously evaluates the capacity of contemporary large language models (LLMs), LLM-powered agents, code assistants, and RAG systems to generate version-specific code that demonstrates functional accuracy through execution. Our extensive evaluations indicate that state-of-the-art systems encounter significant challenges with this task; enterprise models achieving baseline success rates in the 48-51% range, underscoring the intricacy of the problem. By offering an execution-based benchmark emphasizing the dynamic nature of code libraries, GitChameleon enables a clearer understanding of this challenge and helps guide the development of more adaptable and dependable AI code generation methods. We will publicly release the dataset and evaluation code upon acceptance.
@misc{misra2025gitchameleonevaluatingaicode,
title={GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities},
author={Diganta Misra and Nizar Islah and Victor May and Brice Rauby and Zihan Wang and Justine Gehring and Antonio Orvieto and Muawiz Chaudhary and Eilif B. Muller and Irina Rish and Samira Ebrahimi Kahou and Massimo Caccia},
year={2025},
eprint={2507.12367},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2507.12367},
}
Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs. Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs. We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over 50 conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs. Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP). CEP significantly improves the performance of various DMs in both pre-training and downstream tasks. We hope that our study provides new insights into understanding the data and pre-training processes of DMs.
@misc{chen2024slight,
title={Slight Corruption in Pre-training Data Makes Better Diffusion Models},
author={Hao Chen and Yujin Han and Diganta Misra and Xiang Li and Kai Hu and Difan Zou and Masashi Sugiyama and Jindong Wang and Bhiksha Raj},
year={2024},
eprint={2405.20494},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
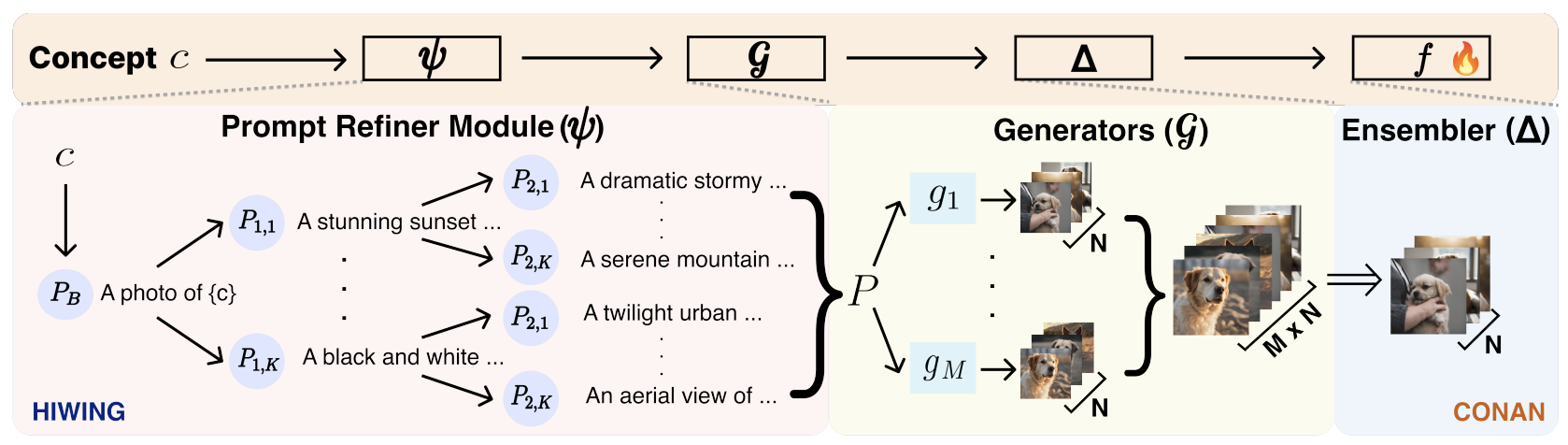
In real-world scenarios, extensive manual annotation for continual learning is impractical due to prohibitive costs. Although prior arts, influenced by large-scale webly supervised training, suggest leveraging web-scraped data in continual learning, this poses challenges such as data imbalance, usage restrictions, and privacy concerns. Addressing the risks of continual webly supervised training, we present an online continual learning framework - Generative Name only Continual Learning (G-NoCL). The proposed G-NoCL uses a set of generators G along with the learner. When encountering new concepts (i.e., classes), G-NoCL employs the novel sample complexity-guided data ensembling technique DIverSity and COmplexity enhancing ensemBlER (DISCOBER) to optimally sample training data from generated data. Through extensive experimentation, we demonstrate superior performance of DISCOBER in G-NoCL online CL benchmarks, covering both In-Distribution (ID) and Out-of-Distribution (OOD) generalization evaluations, compared to naive generator-ensembling, web-supervised, and manually annotated data.
@misc{seo2024just,
title={Just Say the Name: Online Continual Learning with Category Names Only via Data Generation},
author={Minhyuk Seo and Diganta Misra and Seongwon Cho and Minjae Lee and Jonghyun Choi},
year={2024},
eprint={2403.10853},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Mila CERC AAI AI & Scale Workshop 2024 Talk
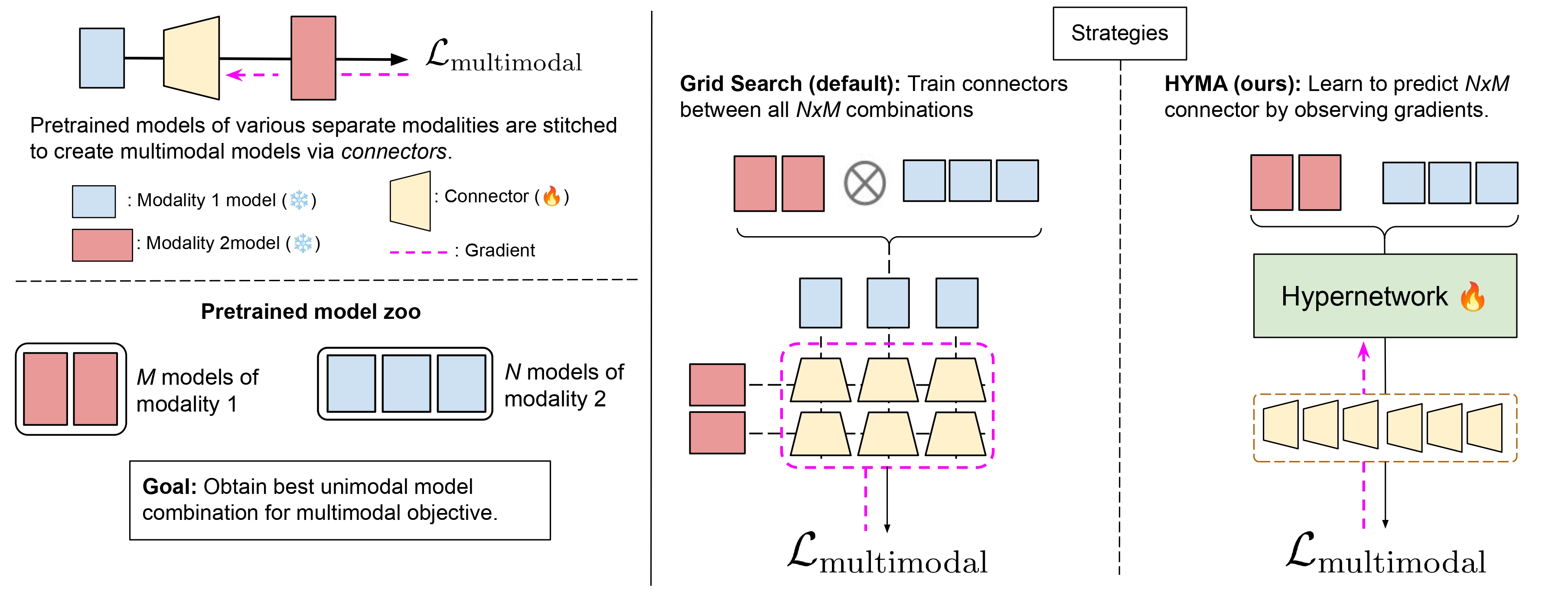
Foundation multi-modal models are often designed by stitching of multiple existing pretrained uni-modal models: for example, an image classifier with an text model. This stitching process is performed by training a connector module that aims to align the representation spaces of these uni-modal models towards a multi-modal objective. However, given the complexity of training such connectors on large scale web-based datasets coupled with the ever-increasing number of available pretrained uni-modal models, the task of uni-modal models selection and subsequent connector module training becomes computationally demanding. To address this under-studied critical problem, we propose Hypernetwork Model Alignment (Hyma), a novel all-in-one solution for optimal uni-modal model selection and connector training by leveraging hypernetworks. Specifically, our framework utilizes the parameter prediction capability of a hypernetwork to obtain jointly trained connector modules for N×M combinations of uni-modal models. In our experiments, Hyma reduces the cost of searching for the best performing uni-modal model pair by 10×, while matching the ranking and trained connector performance obtained via grid search across a suite of diverse multi-modal benchmarks.
@misc{singh2025almostfreemodalitystitching,
title={(Almost) Free Modality Stitching of Foundation Models},
author={Jaisidh Singh and Diganta Misra and Boris Knyazev and Antonio Orvieto},
year={2025},
eprint={2507.10015},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.10015},
}
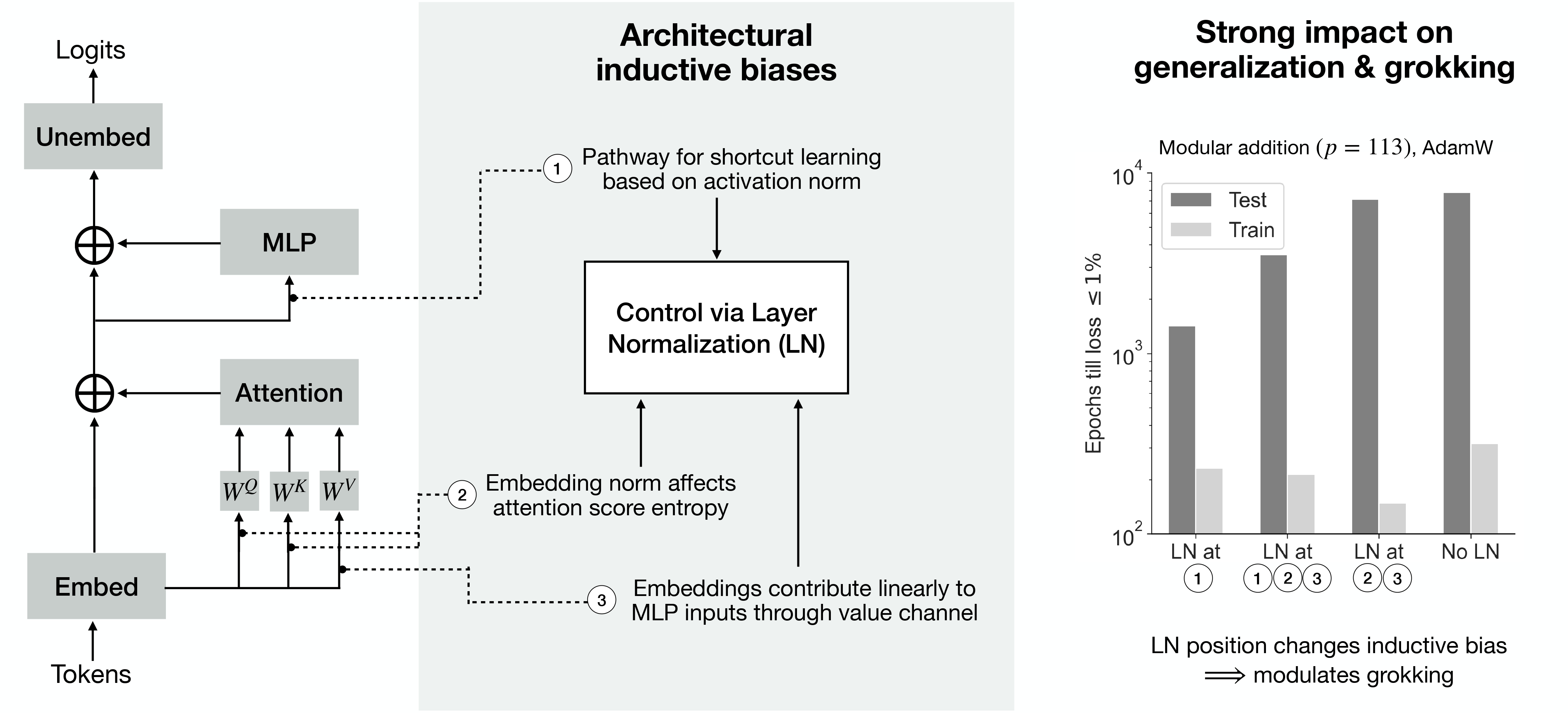
We investigate grokking in transformers through the lens of inductive bias: dispositions arising from architecture or optimization that let the network prefer one solution over another. We first show that architectural choices such as the position of Layer Normalization (LN) strongly modulates grokking speed. This modulation is explained by isolating how LN on specific pathways shapes shortcut-learning and attention entropy. Subsequently, we study how different optimization settings modulate grokking, inducing distinct interpretations of previously proposed controls such as readout scale. Particularly, we find that using readout scale as a control for lazy training can be confounded by learning rate and weight decay in our setting. Accordingly, we show that features evolve continuously throughout training, suggesting grokking in transformers can be more nuanced than a lazy-to-rich transition of the learning regime. Finally, we show how generalization predictably emerges with feature compressibility in grokking, across different modulators of inductive bias.
@misc{singh2026explaininggrokkingtransformerslens,
title={Explaining Grokking in Transformers through the Lens of Inductive Bias},
author={Jaisidh Singh and Diganta Misra and Antonio Orvieto},
year={2026},
eprint={2602.06702},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.06702},
}
AI coding assistants are rapidly becoming integral to modern software development. A key challenge in this space is the continual need to migrate and modernize codebases in response to evolving software ecosystems. Traditionally, such migrations have relied on rule-based systems and human intervention. With the advent of powerful large language models (LLMs), AI-driven agentic frameworks offer a promising alternative—but their effectiveness remains underexplored. In this paper, we introduce FreshBrew, a novel benchmark for evaluating AI agents on project-level Java migrations, with a specific focus on measuring an agent's ability to preserve program semantics and avoid reward hacking, which we argue requires projects with high test coverage for a rigorous and reliable evaluation. We benchmark several state-of-the-art LLMs, and compare their performance against established rule-based tools. Our evaluation of AI agents on this benchmark of 228 repositories shows that the top-performing model, Gemini 2.5 Flash, can successfully migrate 54.3% of projects to JDK 17. Our empirical analysis reveals novel insights into the critical strengths and limitations of current agentic approaches, offering actionable insights into their real-world applicability. By releasing FreshBrew publicly upon acceptance, we aim to facilitate rigorous, reproducible evaluation and catalyze progress in AI-driven codebase modernization.
@misc{may2025freshbrewbenchmarkevaluatingai,
title={FreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration},
author={Victor May and Diganta Misra and Yanqi Luo and Anjali Sridhar and Justine Gehring and Silvio Soares Ribeiro Junior},
year={2025},
eprint={2510.04852},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2510.04852},
}
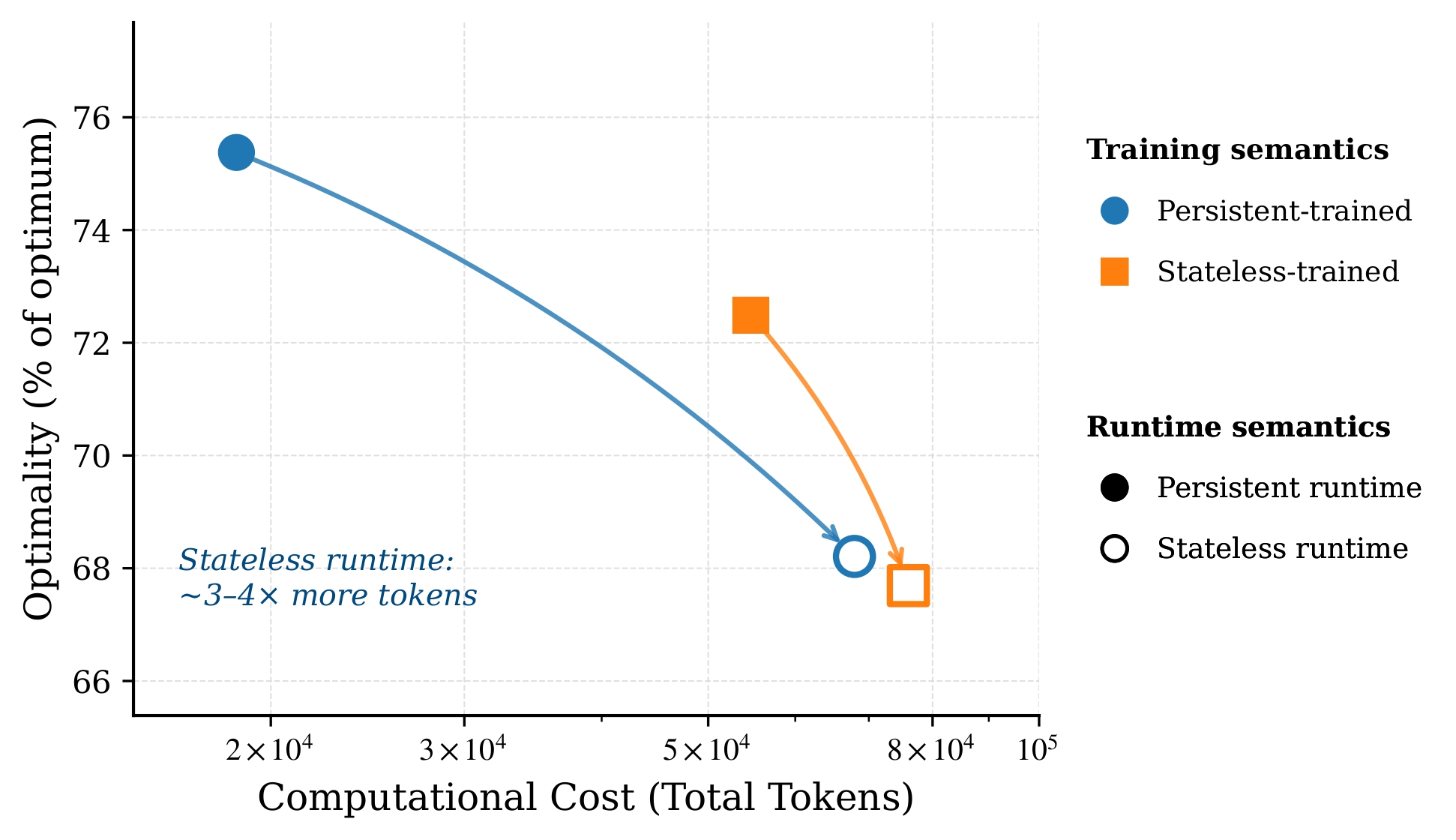
Tool-augmented LLMs are increasingly deployed as agents that interleave natural-language reasoning with executable Python actions, as in CodeAct-style frameworks. In deployment, these agents rely on runtime state that persists across steps. By contrast, the traces used to post-train these models rarely encode how interpreter state is managed. We ask whether interpreter persistence is merely a runtime scaffold, or a property of the training data that shapes how agents learn to use the interpreter.
We isolate state persistence as a training-time variable. We introduce Opaque Knapsack, a procedurally generated family of partially observable optimization tasks designed to prevent one-shot solutions. Item attributes and constraints are hidden behind budgeted tool calls, forcing multi-turn control flow and iterative state revision. Holding task instances, prompts, tools, model, and supervision fixed, we generate matched trajectories differing only in whether interpreter state persists across steps or resets after each action. We then fine-tune identical base models (Qwen3-8B) on each trace variant and evaluate all four train-runtime combinations.
Our 2x2 cross-evaluation shows that interpreter persistence shapes how agents reach solutions, not whether they do: solution quality is statistically indistinguishable across conditions, but token cost and stability differ substantially. A persistent-trained model in a stateless runtime triggers missing-variable errors in roughly 80% of episodes; a stateless-trained model in a persistent runtime redundantly re-derives retained state, using roughly 3.5x more tokens.
Interpreter persistence should be treated as a first-class semantic of agent traces. Aligning fine-tuning data with deployment runtimes improves efficiency and reduces brittle train-runtime mismatches.
@misc{may2026agentslearnruntimeinterpreter,
title={Agents Learn Their Runtime: Interpreter Persistence as Training-Time Semantics},
author={Victor May and Aaditya Salgarkar and Yishan Wang and Diganta Misra and Huu Nguyen},
year={2026},
eprint={2603.01209},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2603.01209},
}
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
@misc{longpre2024consentcrisisrapiddecline,
title={Consent in Crisis: The Rapid Decline of the AI Data Commons},
author={Shayne Longpre and Robert Mahari and Ariel Lee and Campbell Lund and Hamidah Oderinwale and William Brannon and Nayan Saxena and Naana Obeng-Marnu and Tobin South and Cole Hunter and Kevin Klyman and Christopher Klamm and Hailey Schoelkopf and Nikhil Singh and Manuel Cherep and Ahmad Anis and An Dinh and Caroline Chitongo and Da Yin and Damien Sileo and Deividas Mataciunas and Diganta Misra and Emad Alghamdi and Enrico Shippole and Jianguo Zhang and Joanna Materzynska and Kun Qian and Kush Tiwary and Lester Miranda and Manan Dey and Minnie Liang and Mohammed Hamdy and Niklas Muennighoff and Seonghyeon Ye and Seungone Kim and Shrestha Mohanty and Vipul Gupta and Vivek Sharma and Vu Minh Chien and Xuhui Zhou and Yizhi Li and Caiming Xiong and Luis Villa and Stella Biderman and Hanlin Li and Daphne Ippolito and Sara Hooker and Jad Kabbara and Sandy Pentland},
year={2024},
eprint={2407.14933},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.14933},
}
Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
@misc{longpre2024bridgingdataprovenancegap,
title={Bridging the Data Provenance Gap Across Text, Speech and Video},
author={Shayne Longpre and Nikhil Singh and Manuel Cherep and Kushagra Tiwary and Joanna Materzynska and William Brannon and Robert Mahari and Manan Dey and Mohammed Hamdy and Nayan Saxena and Ahmad Mustafa Anis and Emad A. Alghamdi and Vu Minh Chien and Naana Obeng-Marnu and Da Yin and Kun Qian and Yizhi Li and Minnie Liang and An Dinh and Shrestha Mohanty and Deividas Mataciunas and Tobin South and Jianguo Zhang and Ariel N. Lee and Campbell S. Lund and Christopher Klamm and Damien Sileo and Diganta Misra and Enrico Shippole and Kevin Klyman and Lester JV Miranda and Niklas Muennighoff and Seonghyeon Ye and Seungone Kim and Vipul Gupta and Vivek Sharma and Xuhui Zhou and Caiming Xiong and Luis Villa and Stella Biderman and Alex Pentland and Sara Hooker and Jad Kabbara},
year={2024},
eprint={2412.17847},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2412.17847},
}
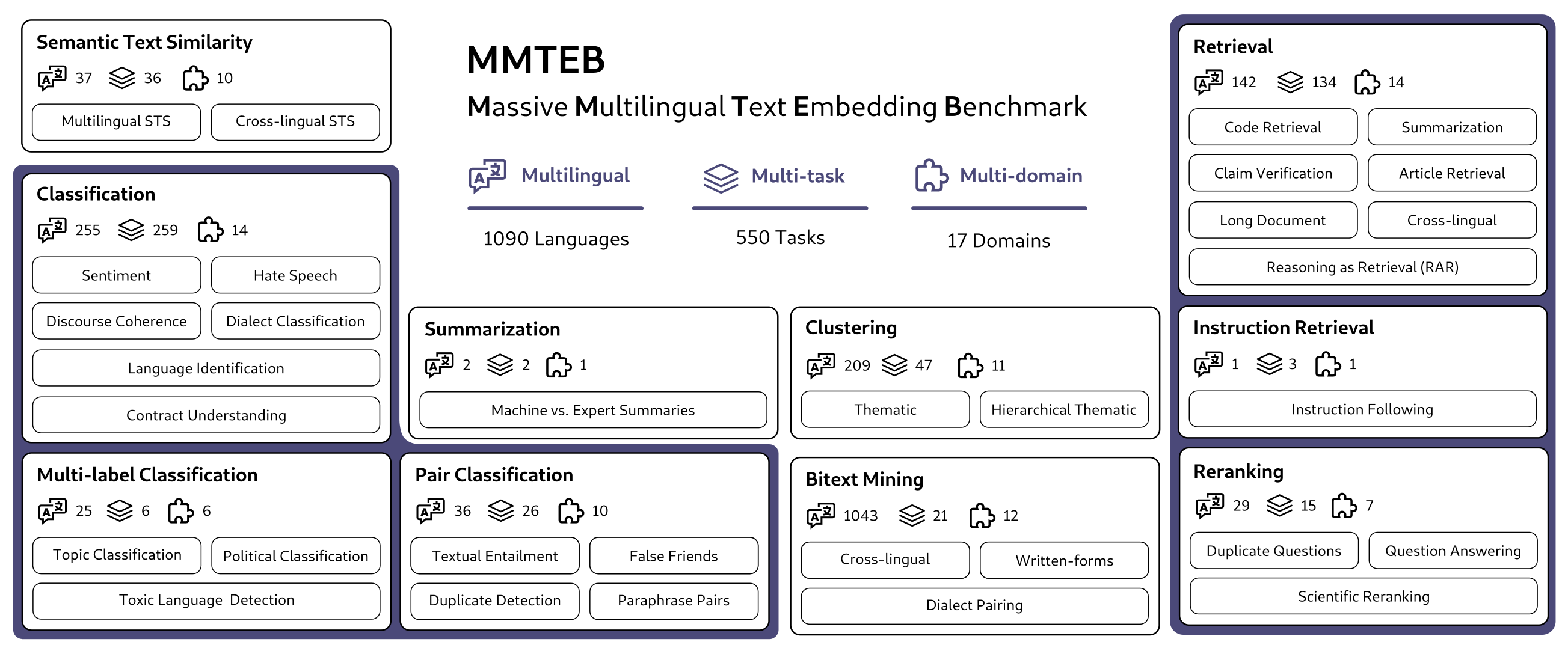
Text embeddings are typically evaluated on a narrow set of tasks, limited in terms of languages, domains, and task types. To circumvent this limitation and to provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) -- a large-scale community-driven initiative expanding MTEB to over 500 \textit{quality controlled} evaluation tasks across 1,000+ languages. MMTEB includes a wide range of challenging novel tasks such as instruction following, long-document retrieval, and code retrieval, and represents the largest multilingual collection of evaluation tasks for embedding models to date. We use this collection to construct multiple highly multilingual benchmarks. We evaluate a representative set of models on these benchmarks. Our findings indicate that, while LLM-based models can achieve state-of-the-art performance on a subset of languages, the best-performing publicly available model across languages is the notably smaller, multilingual-e5-large-instruct. Massive benchmarks often impose high computational demands, limiting accessibility, particularly for low-resource communities. To address this, we downsample tasks based on inter-task correlation (i.e., selecting only a diverse set of tasks) while preserving relative rankings. We further optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks at a significantly lower computational cost. For instance, we introduce a new zero-shot English benchmark that maintains a similar ordering at a fraction of the cost.
@misc{enevoldsen2025mmtebmassivemultilingualtext,
title={MMTEB: Massive Multilingual Text Embedding Benchmark},
author={Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and Márton Kardos and Ashwin Mathur and David Stap and Jay Gala and Wissam Siblini and Dominik Krzemiński and Genta Indra Winata and Saba Sturua and Saiteja Utpala and Mathieu Ciancone and Marion Schaeffer and Gabriel Sequeira and Diganta Misra and Shreeya Dhakal and Jonathan Rystrøm and Roman Solomatin and Ömer Çağatan and Akash Kundu and Martin Bernstorff and Shitao Xiao and Akshita Sukhlecha and Bhavish Pahwa and Rafał Poświata and Kranthi Kiran GV and Shawon Ashraf and Daniel Auras and Björn Plüster and Jan Philipp Harries and Loïc Magne and Isabelle Mohr and Mariya Hendriksen and Dawei Zhu and Hippolyte Gisserot-Boukhlef and Tom Aarsen and Jan Kostkan and Konrad Wojtasik and Taemin Lee and Marek Šuppa and Crystina Zhang and Roberta Rocca and Mohammed Hamdy and Andrianos Michail and John Yang and Manuel Faysse and Aleksei Vatolin and Nandan Thakur and Manan Dey and Dipam Vasani and Pranjal Chitale and Simone Tedeschi and Nguyen Tai and Artem Snegirev and Michael Günther and Mengzhou Xia and Weijia Shi and Xing Han Lù and Jordan Clive and Gayatri Krishnakumar and Anna Maksimova and Silvan Wehrli and Maria Tikhonova and Henil Panchal and Aleksandr Abramov and Malte Ostendorff and Zheng Liu and Simon Clematide and Lester James Miranda and Alena Fenogenova and Guangyu Song and Ruqiya Bin Safi and Wen-Ding Li and Alessia Borghini and Federico Cassano and Hongjin Su and Jimmy Lin and Howard Yen and Lasse Hansen and Sara Hooker and Chenghao Xiao and Vaibhav Adlakha and Orion Weller and Siva Reddy and Niklas Muennighoff},
year={2025},
eprint={2502.13595},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.13595},
}
Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
@article{srivastava2022beyond,
title = {Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models},
author = {Aarohi Srivastava and Abhinav Rastogi and Abhishek Rao and Abu Awal Md Shoeb and Abubakar Abid and Adam Fisch and Adam R. Brown and Adam Santoro and Aditya Gupta and Adrià Garriga-Alonso and Agnieszka Kluska and Aitor Lewkowycz and Akshat Agarwal and Alethea Power and Alex Ray and Alex Warstadt and Alexander W. Kocurek and Ali Safaya and Ali Tazarv and Alice Xiang and Alicia Parrish and Allen Nie and Aman Hussain and Amanda Askell and Amanda Dsouza and Ameet Rahane and Anantharaman S. Iyer and Anders Andreassen and Andrea Santilli and Andreas Stuhlmüller and Andrew Dai and Andrew La and Andrew Lampinen and Andy Zou and Angela Jiang and Angelica Chen and Anh Vuong and Animesh Gupta and Anna Gottardi and Antonio Norelli and Anu Venkatesh and Arash Gholamidavoodi and Arfa Tabassum and Arul Menezes and Arun Kirubarajan and Asher Mullokandov and Ashish Sabharwal and Austin Herrick and Avia Efrat and Aykut Erdem and Ayla Karakaş and B. Ryan Roberts and Bao Sheng Loe and Barret Zoph and Bartłomiej Bojanowski and Batuhan Özyurt and Behnam Hedayatnia and Behnam Neyshabur and Benjamin Inden and Benno Stein and Berk Ekmekci and Bill Yuchen Lin and Blake Howald and Cameron Diao and Cameron Dour and Catherine Stinson and Cedrick Argueta and César Ferri Ramírez and Chandan Singh and Charles Rathkopf and Chenlin Meng and Chitta Baral and Chiyu Wu and Chris Callison-Burch and Chris Waites and Christian Voigt and Christopher D. Manning and Christopher Potts and Cindy Ramirez and Clara E. Rivera and Clemencia Siro and Colin Raffel and Courtney Ashcraft and Cristina Garbacea and Damien Sileo and Dan Garrette and Dan Hendrycks and Dan Kilman and Dan Roth and Daniel Freeman and Daniel Khashabi and Daniel Levy and Daniel Moseguí González and Danny Hernandez and Danqi Chen and Daphne Ippolito and Dar Gilboa and David Dohan and David Drakard and David Jurgens and Debajyoti Datta and Deep Ganguli and Denis Emelin and Denis Kleyko and Deniz Yuret and Derek Chen and Derek Tam and Dieuwke Hupkes and Diganta Misra and Dilyar Buzan and Dimitri Coelho Mollo and Diyi Yang and Dong-Ho Lee and Ekaterina Shutova and Ekin Dogus Cubuk and Elad Segal and Eleanor Hagerman and Elizabeth Barnes and Elizabeth Donoway and Ellie Pavlick and Emanuele Rodola and Emma Lam and Eric Chu and Eric Tang and Erkut Erdem and Ernie Chang and Ethan A. Chi and Ethan Dyer and Ethan Jerzak and Ethan Kim and Eunice Engefu Manyasi and Evgenii Zheltonozhskii and Fanyue Xia and Fatemeh Siar and Fernando Martínez-Plumed and Francesca Happé and Francois Chollet and Frieda Rong and Gaurav Mishra and Genta Indra Winata and Gerard de Melo and Germán Kruszewski and Giambattista Parascandolo and Giorgio Mariani and Gloria Wang and Gonzalo Jaimovitch-López and Gregor Betz and Guy Gur-Ari and Hana Galijasevic and Hannah Kim and Hannah Rashkin and Hannaneh Hajishirzi and Harsh Mehta and Hayden Bogar and Henry Shevlin and Hinrich Schütze and Hiromu Yakura and Hongming Zhang and Hugh Mee Wong and Ian Ng and Isaac Noble and Jaap Jumelet and Jack Geissinger and Jackson Kernion and Jacob Hilton and Jaehoon Lee and Jaime Fernández Fisac and James B. Simon and James Koppel and James Zheng and James Zou and Jan Kocoń and Jana Thompson and Jared Kaplan and Jarema Radom and Jascha Sohl-Dickstein and Jason Phang and Jason Wei and Jason Yosinski and Jekaterina Novikova and Jelle Bosscher and Jennifer Marsh and Jeremy Kim and Jeroen Taal and Jesse Engel and Jesujoba Alabi and Jiacheng Xu and Jiaming Song and Jillian Tang and Joan Waweru and John Burden and John Miller and John U. Balis and Jonathan Berant and Jörg Frohberg and Jos Rozen and Jose Hernandez-Orallo and Joseph Boudeman and Joseph Jones and Joshua B. Tenenbaum and Joshua S. Rule and Joyce Chua and Kamil Kanclerz and Karen Livescu and Karl Krauth and Karthik Gopalakrishnan and Katerina Ignatyeva and Katja Markert and Kaustubh D. Dhole and Kevin Gimpel and Kevin Omondi and Kory Mathewson and Kristen Chiafullo and Ksenia Shkaruta and Kumar Shridhar and Kyle McDonell and Kyle Richardson and Laria Reynolds and Leo Gao and Li Zhang and Liam Dugan and Lianhui Qin and Lidia Contreras-Ochando and Louis-Philippe Morency and Luca Moschella and Lucas Lam and Lucy Noble and Ludwig Schmidt and Luheng He and Luis Oliveros Colón and Luke Metz and Lütfi Kerem Şenel and Maarten Bosma and Maarten Sap and Maartje ter Hoeve and Madotto Andrea and Maheen Farooqi and Manaal Faruqui and Mantas Mazeika and Marco Baturan and Marco Marelli and Marco Maru and Maria Jose Ramírez Quintana and Marie Tolkiehn and Mario Giulianelli and Martha Lewis and Martin Potthast and Matthew L. Leavitt and Matthias Hagen and Mátyás Schubert and Medina Orduna Baitemirova and Melody Arnaud and Melvin McElrath and Michael A. Yee and Michael Cohen and Michael Gu and Michael Ivanitskiy and Michael Starritt and Michael Strube and Michał Swędrowski and Michele Bevilacqua and Michihiro Yasunaga and Mihir Kale and Mike Cain and Mimee Xu and Mirac Suzgun and Mo Tiwari and Mohit Bansal and Moin Aminnaseri and Mor Geva and Mozhdeh Gheini and Mukund Varma T and Nanyun Peng and Nathan Chi and Nayeon Lee and Neta Gur-Ari Krakover and Nicholas Cameron and Nicholas Roberts and Nick Doiron and Nikita Nangia and Niklas Deckers and Niklas Muennighoff and Nitish Shirish Keskar and Niveditha S. Iyer and Noah Constant and Noah Fiedel and Nuan Wen and Oliver Zhang and Omar Agha and Omar Elbaghdadi and Omer Levy and Owain Evans and Pablo Antonio Moreno Casares and Parth Doshi and Pascale Fung and Paul Pu Liang and Paul Vicol and Pegah Alipoormolabashi and Peiyuan Liao and Percy Liang and Peter Chang and Peter Eckersley and Phu Mon Htut and Pinyu Hwang and Piotr Miłkowski and Piyush Patil and Pouya Pezeshkpour and Priti Oli and Qiaozhu Mei and Qing Lyu and Qinlang Chen and Rabin Banjade and Rachel Etta Rudolph and Raefer Gabriel and Rahel Habacker and Ramón Risco Delgado and Raphaël Millière and Rhythm Garg and Richard Barnes and Rif A. Saurous and Riku Arakawa and Robbe Raymaekers and Robert Frank and Rohan Sikand and Roman Novak and Roman Sitelew and Ronan LeBras and Rosanne Liu and Rowan Jacobs and Rui Zhang and Ruslan Salakhutdinov and Ryan Chi and Ryan Lee and Ryan Stovall and Ryan Teehan and Rylan Yang and Sahib Singh and Saif M. Mohammad and Sajant Anand and Sam Dillavou and Sam Shleifer and Sam Wiseman and Samuel Gruetter and Samuel R. Bowman and Samuel S. Schoenholz and Sanghyun Han and Sanjeev Kwatra and Sarah A. Rous and Sarik Ghazarian and Sayan Ghosh and Sean Casey and Sebastian Bischoff and Sebastian Gehrmann and Sebastian Schuster and Sepideh Sadeghi and Shadi Hamdan and Sharon Zhou and Shashank Srivastava and Sherry Shi and Shikhar Singh and Shima Asaadi and Shixiang Shane Gu and Shubh Pachchigar and Shubham Toshniwal and Shyam Upadhyay and Shyamolima and Debnath and Siamak Shakeri and Simon Thormeyer and Simone Melzi and Siva Reddy and Sneha Priscilla Makini and Soo-Hwan Lee and Spencer Torene and Sriharsha Hatwar and Stanislas Dehaene and Stefan Divic and Stefano Ermon and Stella Biderman and Stephanie Lin and Stephen Prasad and Steven T. Piantadosi and Stuart M. Shieber and Summer Misherghi and Svetlana Kiritchenko and Swaroop Mishra and Tal Linzen and Tal Schuster and Tao Li and Tao Yu and Tariq Ali and Tatsu Hashimoto and Te-Lin Wu and Théo Desbordes and Theodore Rothschild and Thomas Phan and Tianle Wang and Tiberius Nkinyili and Timo Schick and Timofei Kornev and Timothy Telleen-Lawton and Titus Tunduny and Tobias Gerstenberg and Trenton Chang and Trishala Neeraj and Tushar Khot and Tyler Shultz and Uri Shaham and Vedant Misra and Vera Demberg and Victoria Nyamai and Vikas Raunak and Vinay Ramasesh and Vinay Uday Prabhu and Vishakh Padmakumar and Vivek Srikumar and William Fedus and William Saunders and William Zhang and Wout Vossen and Xiang Ren and Xiaoyu Tong and Xinyi Wu and Xudong Shen and Yadollah Yaghoobzadeh and Yair Lakretz and Yangqiu Song and Yasaman Bahri and Yejin Choi and Yichi Yang and Yiding Hao and Yifu Chen and Yonatan Belinkov and Yu Hou and Yufang Hou and Yuntao Bai and Zachary Seid and Zhao Xinran and Zhuoye Zhao and Zijian Wang and Zijie J. Wang and Zirui Wang and Ziyi Wu},
year = {2022},
journal = {arXiv preprint arXiv: Arxiv-2206.04615}
}
Tense task
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations.
@misc{nakamura2024auroram,
title={Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order},
author={Taishi Nakamura and Mayank Mishra and Simone Tedeschi and Yekun Chai and Jason T Stillerman and Felix Friedrich and Prateek Yadav and Tanmay Laud and Vu Minh Chien and Terry Yue Zhuo and Diganta Misra and Ben Bogin and Xuan-Son Vu and Marzena Karpinska and Arnav Varma Dantuluri and Wojciech Kusa and Tommaso Furlanello and Rio Yokota and Niklas Muennighoff and Suhas Pai and Tosin Adewumi and Veronika Laippala and Xiaozhe Yao and Adalberto Junior and Alpay Ariyak and Aleksandr Drozd and Jordan Clive and Kshitij Gupta and Liangyu Chen and Qi Sun and Ken Tsui and Noah Persaud and Nour Fahmy and Tianlong Chen and Mohit Bansal and Nicolo Monti and Tai Dang and Ziyang Luo and Tien-Tung Bui and Roberto Navigli and Virendra Mehta and Matthew Blumberg and Victor May and Huu Nguyen and Sampo Pyysalo},
year={2024},
eprint={2404.00399},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
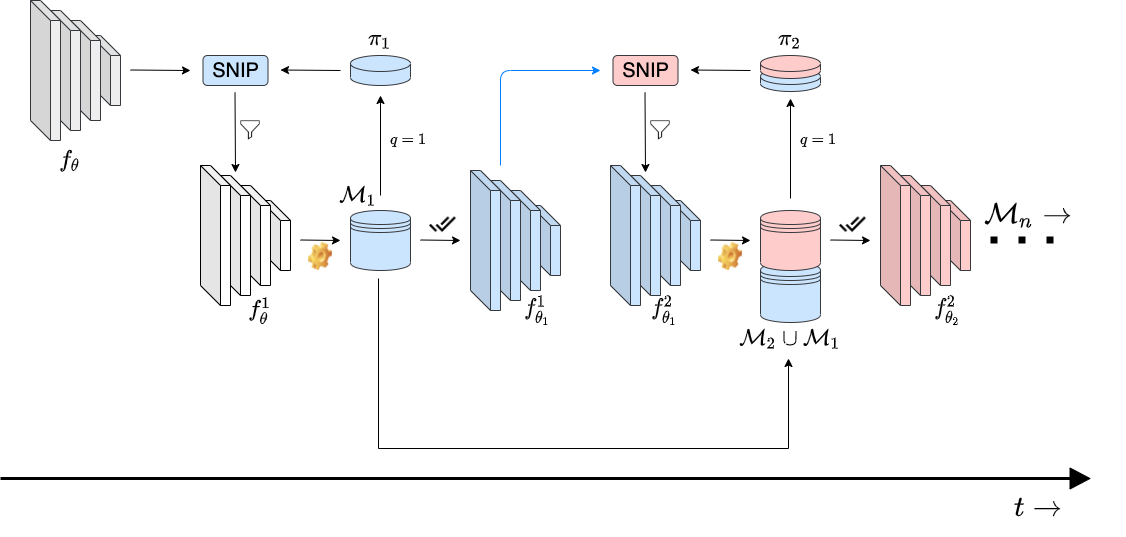
With the latest advances in deep learning, there has been a lot of focus on the online learning paradigm due to its relevance in practical settings. Although many methods have been investigated for optimal learning settings in scenarios where the data stream is continuous over time, sparse networks training in such settings have often been overlooked. In this paper, we explore the problem of training a neural network with a target sparsity in a particular case of online learning: the anytime learning at macroscale paradigm (ALMA). We propose a novel way of progressive pruning, referred to as \textit{Anytime Progressive Pruning} (APP); the proposed approach significantly outperforms the baseline dense and Anytime OSP models across multiple architectures and datasets under short, moderate, and long-sequence training. Our method, for example, shows an improvement in accuracy of $\approx 7\%$ and a reduction in the generalization gap by $\approx 22\%$, while being $\approx 1/3$ rd the size of the dense baseline model in few-shot restricted imagenet training. We further observe interesting nonmonotonic transitions in the generalization gap in the high number of megabatches-based ALMA. The code and experiment dashboards can be accessed at \url{https://github.com/landskape-ai/Progressive-Pruning} and \url{https://wandb.ai/landskape/APP}, respectively.
@misc{misra2022app,
title={APP: Anytime Progressive Pruning},
author={Diganta Misra and Bharat Runwal and Tianlong Chen and Zhangyang Wang and Irina Rish},
year={2022},
eprint={2204.01640},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
NSL presentation /
MLC Research Jam #8 /
MLC Research Jam #9 /
Continual AI Seminar
Learning under constraints has been a fundamental avenue of research in deep learning since the advent of modern deep neural networks. In parallel to the upwards trajectory of scaling neural networks, one practical constraint that has embodied efficient deep learning has been that of sparsity. Unstructured weight sparsity has been the cornerstone of pioneering works in the space of pruning and lottery ticket hypothesis. In this paper, we propose \textbf{$\mathcal{D}^2$-Sparse}, a novel dual dynamic sparse learning system for low-data learning regime. Our paper combines two popular constraints in deep learning namely sparsity and low-data learning, often studied in disjoint paradigms, thus opening new directions of research in sparsity. $\mathcal{D}^2$-Sparse outperforms standard iterative pruning schema when coupled with standard deep networks in computer vision tasks like image classification and in natural language processing like code generation with no extra-overhead cost on inference. Compared to iterative pruning, on $\frac{1}{8}$-th total data budget, $\mathcal{D}^2$-Sparse achieves a $\approx$ 4% top-1 accuracy boost for ResNet-18 on the CIFAR-100 classification task. Further, we demonstrate the effectiveness of the proposed method in anytime learning scenarios and provide extensive analysis into evolution of sparse masks in $\mathcal{D}^2$-Sparse over the training process. Code, dashboard, and model weights will be open-sourced for public access upon acceptance.
@inproceedings{misramathcal,
title={$$\backslash$mathcal $\{$D$\}$\^{} 2$-Sparse: Navigating the low data learning regime with coupled sparse networks},
author={Misra, Diganta and Nolte, Niklas and Mishra, Sparsha and Yin, Lu},
booktitle={5th Workshop on practical ML for limited/low resource settings}
}
In the era of resource-intensive foundation models, efficient adaptation in downstream tasks has become paramount. Visual Prompting (VP), inspired by prompting in Large Language Models (LLMs), has emerged as a key transfer learning method in computer vision. Aligned with the growing significance of efficiency, research in model compression has become pivotal to alleviate the computational burden in both training and deploying over-parameterized neural networks. A key goal in model compression is the development of sparse models capable of matching or surpassing the performance of their over-parameterized, dense counterparts. While prior research has explored the impact of model sparsity on transfer learning, its effects on visual prompting-based transfer remain unclear. This study addresses this gap, revealing that model sparsity adversely affects the performance of visual prompting-based transfer, particularly in low-data-volume scenarios. Furthermore, our findings highlight the negative influence of sparsity on the calibration of downstream visual-prompted models. This empirical exploration calls for a nuanced understanding beyond accuracy in sparse settings, opening avenues for further research in Visual Prompting for sparse models.
@article{misra2023reprogramming,
title = {Reprogramming under constraints: Revisiting efficient and reliable transferability of lottery tickets},
author = {Diganta Misra and Agam Goyal and Bharat Runwal and Pin Yu Chen},
year = {2023},
journal = {arXiv preprint arXiv: 2308.14969}
}
Cohere ForAI Lightning Talk /
Google Sparsity Reading Group Talk /
MLC Research Jam 17
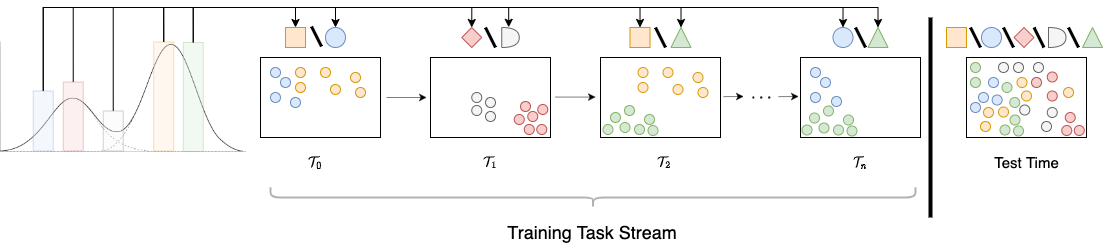
Standard gradient descent algorithms applied to sequences of tasks are known to produce catastrophic forgetting in deep neural networks. When trained on a new task in a sequence, the model updates its parameters on the current task, forgetting past knowledge. This article explores scenarios where we scale the number of tasks in a finite environment. Those scenarios are composed of a long sequence of tasks with reoccurring data. We show that in such setting, stochastic gradient descent can learn, progress, and converge to a solution that according to existing literature needs a continual learning algorithm. In other words, we show that the model performs knowledge retention and accumulation without specific memorization mechanisms. We propose a new experimentation framework, SCoLe (Scaling Continual Learning), to study the knowledge retention and accumulation of algorithms in potentially infinite sequences of tasks. To explore this setting, we performed a large number of experiments on sequences of 1,000 tasks to better understand this new family of settings. We also propose a slight modifications to the vanilla stochastic gradient descent to facilitate continual learning in this setting. The SCoLe framework represents a good simulation of practical training environments with reoccurring situations and allows the study of convergence behavior in long sequences. Our experiments show that previous results on short scenarios cannot always be extrapolated to longer scenarios.
@article{lesort2022scaling,
title = {Scaling the Number of Tasks in Continual Learning},
author = {Timothée Lesort and Oleksiy Ostapenko and Diganta Misra and Md Rifat Arefin and Pau Rodríguez and Laurent Charlin and Irina Rish},
year = {2022},
journal = {arXiv preprint arXiv: Arxiv-2207.04543}
}
The strength of modern large-scale neural networks lies in their ability to efficiently adapt to new tasks with few examples. Although extensive research has investigated the transferability of Vision Transformers (ViTs) to various downstream tasks under diverse constraints, this study shifts focus to explore the transfer learning potential of [V]-Mamba. We compare its performance with ViTs across different few-shot data budgets and efficient transfer methods. Our analysis yields three key insights into [V]-Mamba's few-shot transfer performance: (a) [V]-Mamba demonstrates superior or equivalent few-shot learning capabilities compared to ViTs when utilizing linear probing (LP) for transfer, (b) Conversely, [V]-Mamba exhibits weaker or similar few-shot learning performance compared to ViTs when employing visual prompting (VP) as the transfer method, and (c) We observe a weak positive correlation between the performance gap in transfer via LP and VP and the scale of the [V]-Mamba model. This preliminary analysis lays the foundation for more comprehensive studies aimed at furthering our understanding of the capabilities of [V]-Mamba variants and their distinctions from ViTs.
@misc{misra2024lowshot,
title={On the low-shot transferability of [V]-Mamba},
author={Diganta Misra and Jay Gala and Antonio Orvieto},
year={2024},
eprint={2403.10696},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
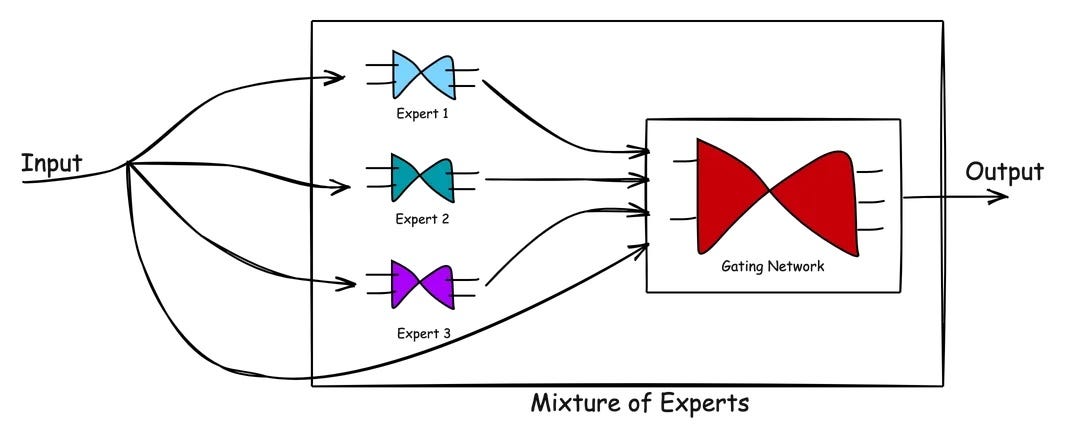
The recent success of Sparse Mixture-of-Experts (SMoEs) models has sparked renewed interest in routed networks in deep learning. A prominent aspect of the SMoE is the scaling of the number of total parameters in a model, effectively increasing capacity while keeping computation costs similar to dense models. Yet, these models pose optimization challenges as inputs are routed discretely to experts in each layer. Often, a regularization term is added to the loss function to penalize the imbalanced selection of experts. We aim to demonstrate that the heuristic regularization strategies used in recent SMoEs, while successful in some tasks, have significant limitations which we aim to address. In multi-domain or multi-task settings, without explicit knowledge of the task or domain, the network will suffer from a mode collapse-performance tradeoff, in which some experts will receive significantly less training signal, or performance on some tasks will suffer. Second, we derive a theoretical basis of the various routing functions, with entropy-maximization as a common objective. Third, we will demonstrate a first application of Generative Flow Networks (GFlowNets) to SMoEs, with a state, policy, and action space, represented at a particular layer of the model by the input, routing network, and sampling from expert probabilities, respectively. We aim to show that SMoEs trained with the Trajectory Balance objective from GFlowNet literature can achieve competitive performance with state of the art routing methods, such as Switch Transformer, and suffer less from expert collapse in multi-task (NYUv2, Pascal-Context) and multi-domain (Omniglot) settings. This work lays some foundations for further exploration of theoretically motivated approaches to routing in sparse MoEs.
The size and prevalence of large language models (LLMs) make them an apt target for model compression. Most LLMs consist of a Transformer encoder and decoder, which each have 6 to 12 layers of multiheaded self-attention blocks, along with fully connected layers. This results in a large number of parameters, making them quite expensive to train and query. Our work focuses on finding techniques to prune CodeBERT, a specific LLM trained to work multimodally between text and code. We explore the effects of structured and unstructured magnitude pruning on the encoder layers of CodeBERT, evaluating on the task of generating natural language comments from a piece of Ruby code.
@article{gupruning,
title={Pruning CodeBERT for Improved Code-to-Text Efficiency},
author={Gu, Alex and Sonecha, Ria and Vedantam, Saaketh and Runwal, Bharat and Misra, Diganta}
}
poster
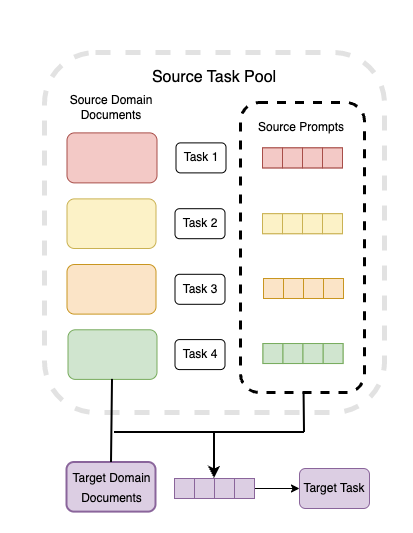
Dense information retrieval yields strong in-domain performance,
but often struggles with out-of-domain generalization, lagging be-
hind unsupervised methods. Retrieval tasks can vary across a num-
ber of dimensions including domain, query intent, and language.
Using a single dense retrieval model for all tasks often underper-
forms lexical methods such as BM25. For practical information
retrieval systems, it is expensive to deploy a different model for
each task. Therefore, our motivation is to develop a cheap and
effective information retrieval model that maintains strong per-
formance across different domains while easily adapting to any
new domain. Other approaches to domain transfer in information
retrieval rely on large auxiliary language models or datasets and
create a separate model for each task. In this work, we develop a
method utilizing prompt tuning to efficiently adapt dense retrievers
with a minimal amount of additional computation. By combining
models trained on a variety of different domains, we can effectively
boost performance on a target task in a new domain. Specifically,
we train dense retrieval models using prompt tuning on a large
number of information retrieval tasks across diverse domains and
types of query intents. To adapt to a new domain, we create new
prompt embeddings by averaging the prompt embeddings from a
set of source tasks selected in an unsupervised manner. We evaluate
zero-shot transfer performance across a wide variety of information
retrieval domains and show competitive performance while lever-
aging a minimal amount of compute. Notably, our SPIRIT method
achieves while being extremely lightweight and practical to deploy
in production.
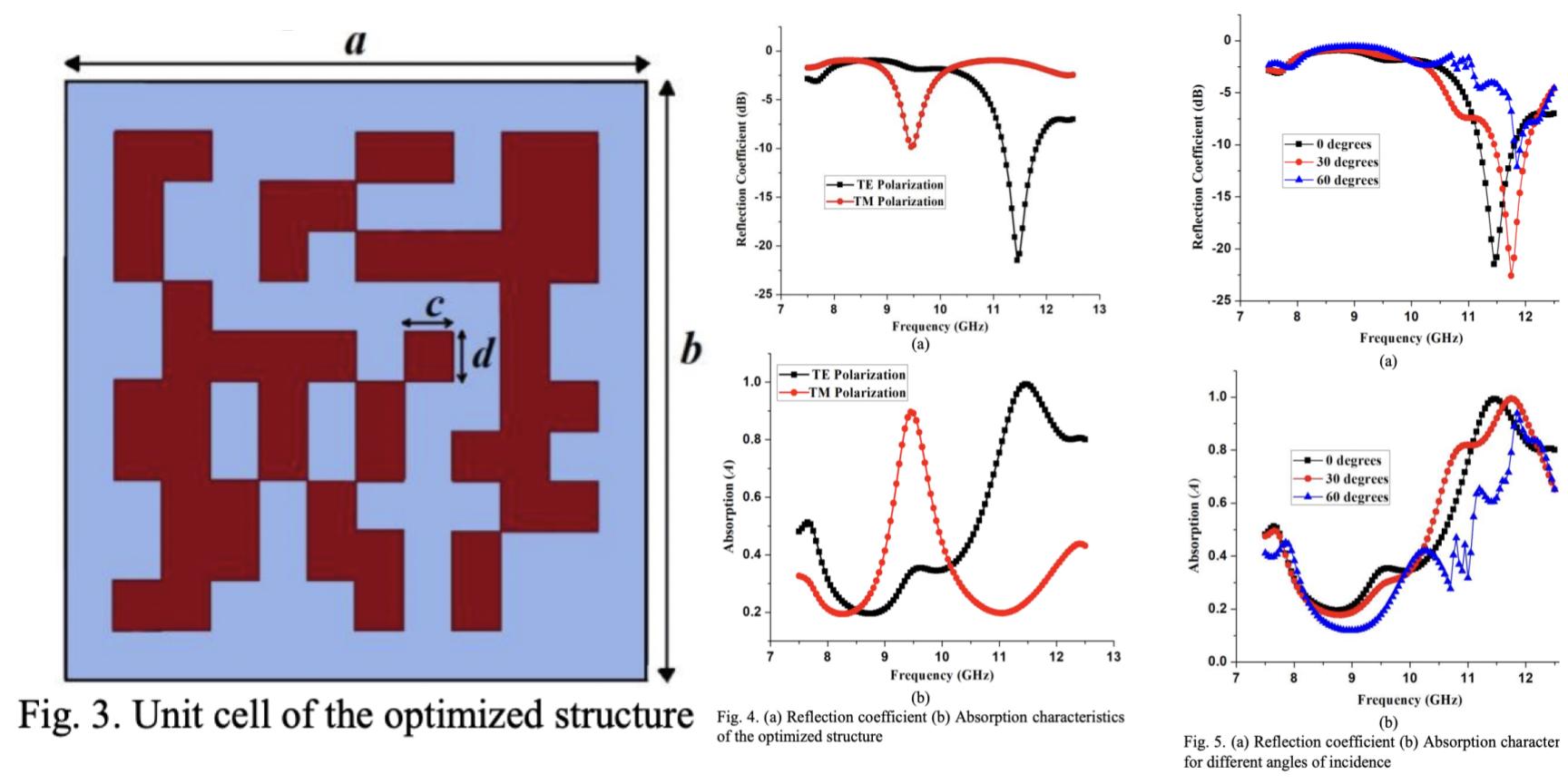
Printable electronics based electromagnetic absorbers are receiving increasing attention of the electromagnetic community because of their unprecedented advantages. This paper presents the design of printable electromagnetic absorbers for the X band. The design of the absorber is optimized using the Genetic Algorithm (GA) to enhance the absorptivity and the absorption bandwidth. The design involves the placement of several square-shaped conductive ink at optimal locations on the paper substrate such that desired absorption characteristics are obtained. Simulations are carried out using the HFSS simulation software. The optimized structure offers an absorptivity of more than 90% in the X band thereby proving to be a viable solution for stealth applications.
@inproceedings{misra2018genetic,
title={Genetic Algorithm Optimized Inkjet Printed Electromagnetic Absorber on Paper Substrate},
author={Misra, Diganta and Pelluri, Rahul and Verma, Vijay Kumar and Appasani, Bhargav and Gupta, Nisha},
booktitle={2018 International Conference on Applied Electromagnetics, Signal Processing and Communication (AESPC)},
volume={1},
pages={1--3},
year={2018},
organization={IEEE}
}
In this paper, we propose an unsupervised learning approach with an objective to understand gene expressions for analysis of Wilson’s disease in the liver of Mus musculus organisms. We proceeded to obtain the best parameters for cluster division to correctly classify gene expression sets so as to capture the effect and characteristics of the disease in the genome levels of the organisms in the best possible way. The clustering proved beneficial in capturing the correct genetic analogy of Wilson’s disease. Analytical experiments were carried out using various clustering algorithms and were evaluated using performance metrics including silhouette score analysis and Calinski–Harabasz index.
@inproceedings{misra2019large,
title={Large-Scale Meta-Analysis of Genes Encoding Pattern in Wilson’s Disease},
author={Misra, Diganta and Tiwari, Anurag and Chaturvedi, Amrita},
booktitle={Advances in Computer Communication and Computational Sciences: Proceedings of IC4S 2018},
pages={389--400},
year={2019},
organization={Springer}
}
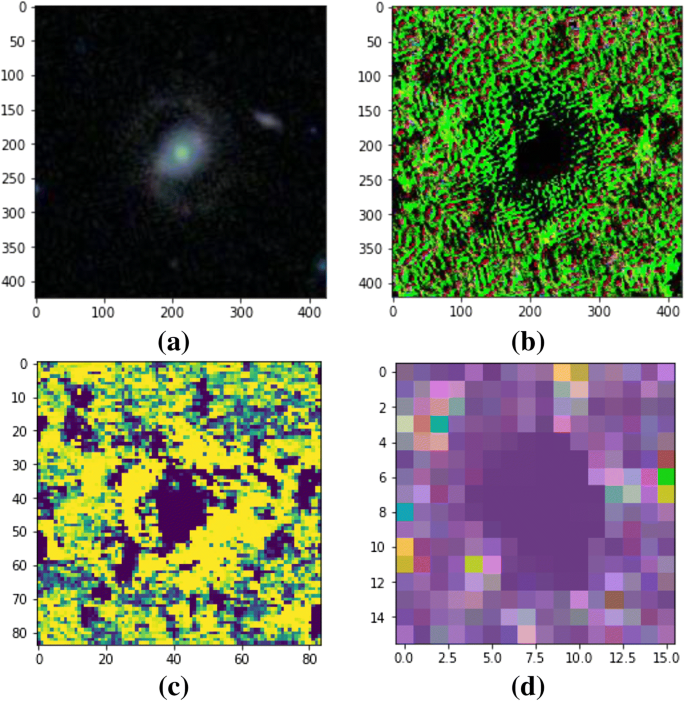
In this paper, a deep learning-based approach has been developed to classify the images of galaxies into three major categories, namely, elliptical, spiral, and irregular. The classifier successfully classified the images with an accuracy of 97.3958%, which outperformed conventional classifiers like Support Vector Machine and Naive Bayes. The convolutional neural network architecture involves one input convolution layer having 16 filters, followed by 4 hidden layers, 1 penultimate dense layer, and an output Softmax layer. The model was trained on 4614 images for 200 epochs using NVIDIA-DGX-1 Tesla-V100 Supercomputer machine and was subsequently tested on new images to evaluate its robustness and accuracy.
@incollection{misra2020convoluted,
title={Convoluted cosmos: classifying galaxy images using deep learning},
author={Misra, Diganta and Mohanty, Sachi Nandan and Agarwal, Mohit and Gupta, Suneet K},
booktitle={Data Management, Analytics and Innovation},
pages={569--579},
year={2020},
publisher={Springer}
}
I am an active lead maintainer of the Reproducible Continual Learning framework by Avalanche and
also actively work on the evaluation framework of Avalanche mainly in the direction of integration of Weights & Biases API.
Echo is an OSS deep learning package with support for TensorFlow, PyTorch and MegEngine, containing novel validated methods, components and building blocks used in deep learning.
I am currently the lead for the modelling part of the Multi-Domain Expert Layers (MDEL) Training: How to increase knowledge without breaking the bank? as a collaborative effort co-ordinated by Ontocord AI wherein my team is working on different aspects of architecture design and training of the MDEL model on SUMMIT supercomputer cluster as part of the INCITE allocation.
I currently work as one of the primary researchers in the synthetic data generation pipeline for subsequent training of a safe (under EU AI Safety Act) and reliable LMM. Our project is generously supported by a compute grant from CINECA utilizing the Leonardo Supercomputer.
Data Science InternJun. 2018 - Feb. 2019 CSIR-CDRI
During this internship, I was involved in building the analytical pipeline, data collection, pre-processing of data, cleaning of data, Geo-spatial Analysis of data and Document writing for the project on understanding demographics of Venture Capital and
Early Seed Investments. As a part of a team of three, I was advised and mentored by Dr. Sukant Khurana.
Served as a primary instructor for cultural engagements along with teaching basic
english and computer science to primary grade students at RangsonWittaya School,
Nakhon Sawan under the AIESEC SDG #4 programme. Was also part of culture
exchange, entrepreneurship and social service programs at Bangkok University
I was responsible for developing the content for the Strategies section in the Continual Learning lecture of the Deep Learning Cohort of Neuromatch Academy 2021.
I was the lead organizer of the W&B MLRC 2021 where I actively supported our challenge participants. Our mission of organizing this challenge was
to make machine learning research reproducible, transparent and accessible to everyone. This initiative was also supported by our W&B MLRC Grant of $500 for each participant.
I was awarded the UNIQUE AI Excellence Scholarship worth CAD$10,000 for the academic year 2022. Under this scholarship, I will be working with Irina Rish and Pouya Bashivan on dynamic sparsity based research.